现如今制作图表的工具非常之多,就好比今天小编带来的Stata 17,作为一款非常实用且操作简单的图表绘制软件,可以帮助用户轻轻松松解决制作上的难题,因为它的功能十分的全面,用户所碰到的难题都可以迎刃而解,并且不需要很复杂的操作即可完成,所以得到了非常多用户的喜爱和追捧。那到底有哪些功能呢?首先就是它的管理功能,能够把所有的文件以及图表统一规范起来,并且可以贴上标签,以便用户在需要的时候,能够更加快速的查寻到,非常的方便;然后就是分析功能,可以把用户所制作出来的图表整理分析,可以设置条件来具体得出分析结果,并且还有着多维元分析的能力,能够把多个数据放在一起整合出来最优的结果;最后就是绘制定量的数据功能,根据用户的需要来制作出符合需要的图表,能够有效的节省用户大量的时间,并且可以提高使用的效率;还有超多的强大功能等待用户去挖掘去使用。此外,作为该系列中的最新版本,还更新了很多的新功能,可以更加方便用户的使用,并且它还在不断的升级和优化之中,以致于把最好的一面展示出来。我们这款
Stata 17破解版,在用户下载的文件中,不仅仅有着软件的安装程序,还有破解补丁,用户需要参考下面的操作即可完美破解,使用全部的功能。有需要的小伙伴们,快来本站下载吧!!!
Stata 17破解版安装教程
1、在麦葱站下载软件压缩包并解压文件。

2、解压后就会得到软件的安装程序以及破解文件。

3、点击安装程序后,正在加载软件的安装向导。
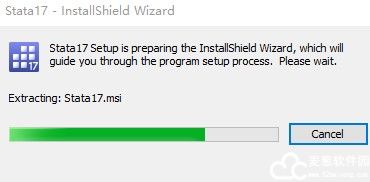
4、加载完成后,就会出现软件的安装向导,点击下一步。
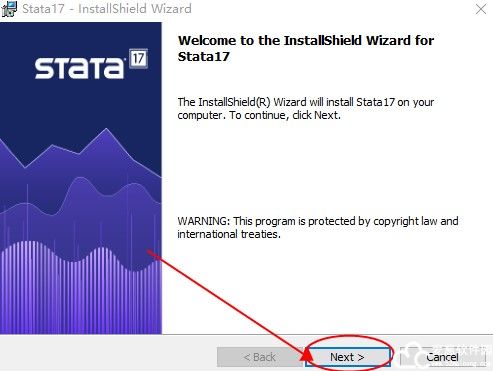
5、用户需要阅读一下软件的协议许可条款,之后再点击我同意。
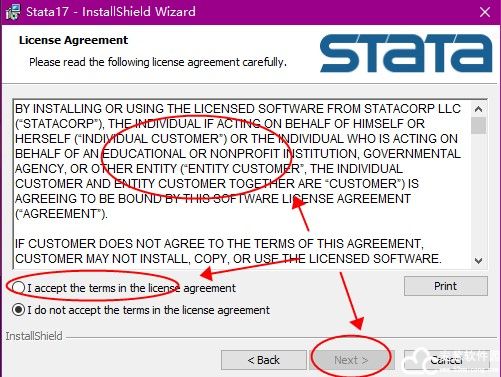
6、填写用户的个人信息以及公司信息。
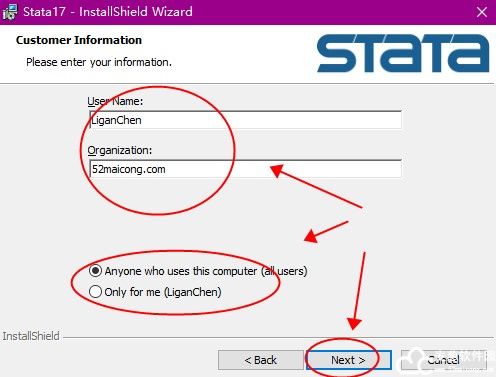
7、根据需要选择一个需要的组件,在前面勾选即可。
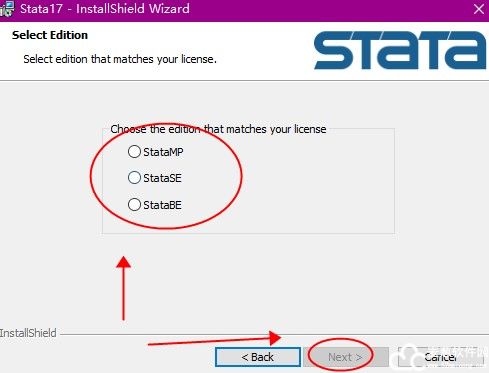
8、更改软件的安装路径,默认是C盘,用户可以修改至其他空余的磁盘中。
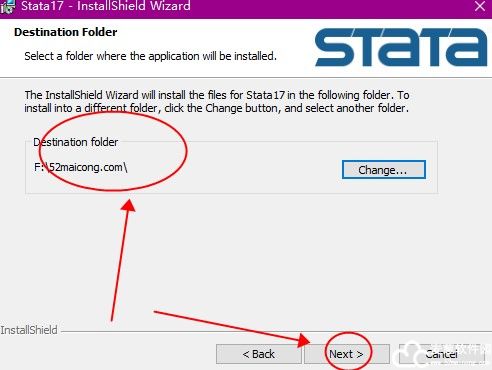
9、然后再选择默认工作目录,点击下一步。
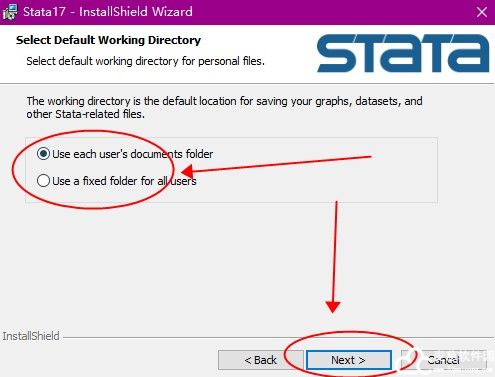
10、一切准备就绪后,就可以点击安装软件。
11、正在安装,稍等片刻。
12、安装完成后,点击退出,先不要打开软件。
stata 17破解教程
1、回到刚刚下载的文件夹中,找到Crck文件。

2、把里面的破解文件复制粘贴到软件的安装目录中。
3、之后就会弹出替换目标中的文件,点击即可完成破解。
4、紧接着点击软件的启动程序。
5、正常打开软件,即表明破解成功,用户可以免费使用全部的功能。
软件优势
1、Stata 17破解版有着新的元分析套件;改进和扩展选择建模(边距适用于所有地方)
2、Python和软件的集成;贝叶斯预测,多链和更多。
3、面板数据扩展回归模型(ERM);导入SAS和SPSS数据集。
4、灵活的非参数序列回归;内存中的多个数据集,即帧。
5、置信区间样本大小分析;非线性DSGE模型。
6、多组IRT;Heckman选择面板数据模型。
7、滞后NLME:多剂量药代动力学模型等。
8、Heteroskedastic命令probit;图形大小为英寸、厘米和打印机点。
9、Mata中的数值积分;Mata中的线性编程。
10、文件编辑器:自动完成,语法高亮等。;formac:暗模式和标签窗口。
stata 17使用教程
1、在软件的最上面一栏中,点击文件下来,可以打开本地文件或者是数据子集等。
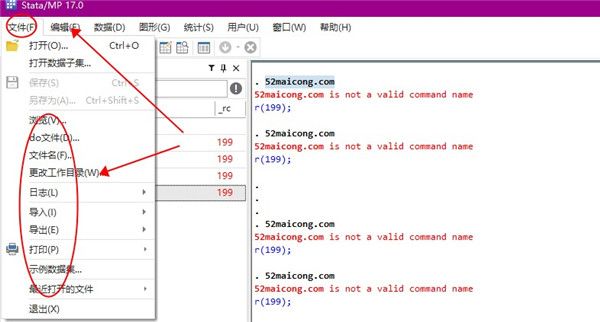
2、如果想要清楚结果窗口,可以在编辑选项中找到,并且还能够设置首选项参数。
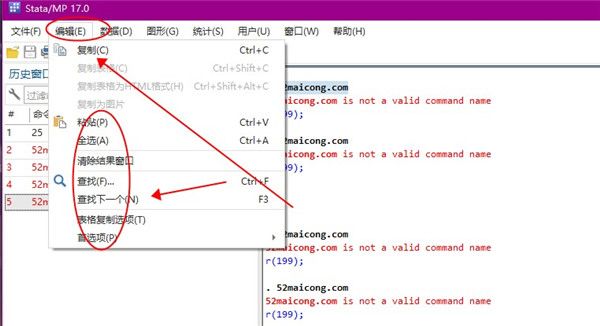
3、想要对数据编辑器做出修改的话,可以在数据中更改,并且可以创建数据等功能。
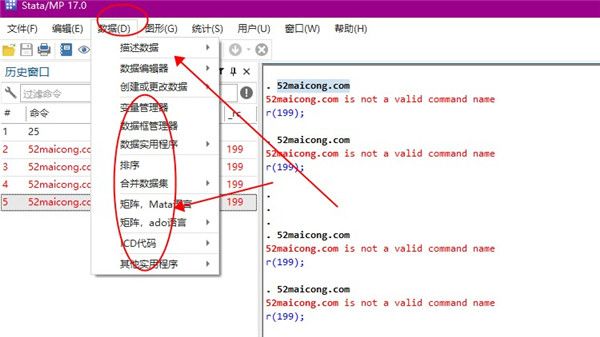
4、有很多的图像用户可以设置,二维图、条形图、点图以及饼图等多种图形可供用户选择。
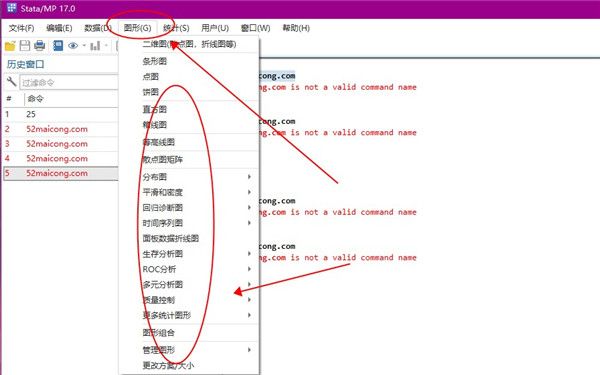
5、统计选项可以帮助用户汇总表格以及分类和序数的结果,并且有着多种模型可以使用。
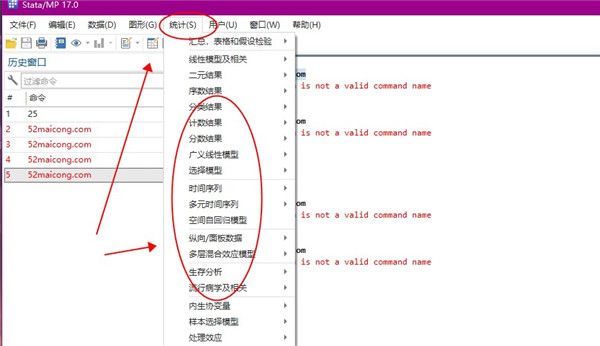
6、用户可以把自己常用的数据、图形以及统计的数据保存到本地,之后就可以快速查看了。
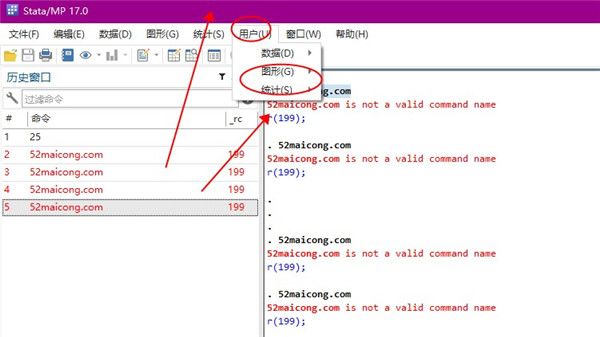
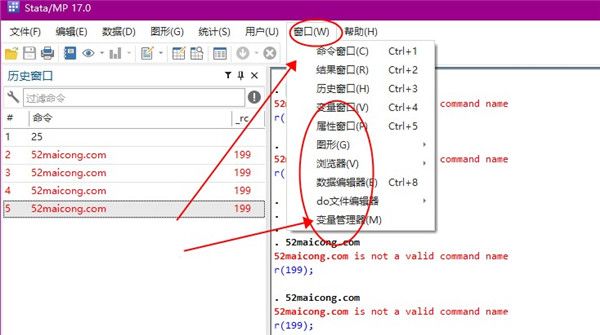
7、对于窗口来说,可以设置命令、结果、历史以及变量窗口,并且还能够启动变量管理器。
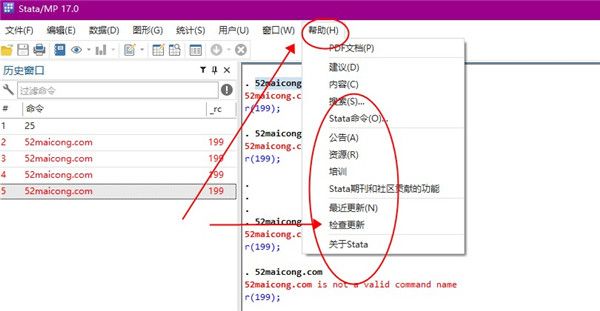
8、如果不知道自己的软件是不是最新版本,可以在帮助中点击检查更新,并且还有公告可以查看。
软件特色
1、该软件具有很强的统计功能。除了传统的统计分析方法,它还收集了近20年发展起来的新方法,如Cox风险回归、指数和Weibull回归、多种结果和有序结果的logistic回归、Poisson回归、负二回归和广义负二回归、随机效应模型等。具体来说,具有以下统计分析能力:
2、数值变量数据的一般分析:参数估计、t检验、单因素和多因素方差分析、协方差分析、交互效应模型、平衡和非平衡设计、嵌套设计、随机效应、多平数两对比、缺项数据处理、方差齐性检验、正态检验、变量转换等。
3、Stata 17破解版中的分类数据的一般分析:参数估计、列联表分析(列联系数、确切概率)、流行病学表格分析等。
4、一般分析等级资料:秩变换、秩检验、秩相关等。
5、回归分析:简单相关,偏相关,典型相关,以及多达数十种回归分析方法,如多元线性回归,逐步回归,加权回归,稳键回归,二阶段回归,百分位数(中位数)回归,残差分析,强影响点分析,曲线拟合,随机效应线性回归模型等。
6、其它方法:质量控制,整组抽样设计效率,诊断测试评价,kappa等。
7、绘图模块主要提供以下八种基本图形:直方图(histogram)、条形图(bar)、条形图(oneway)、圆形图(pie)、散点图(twoway)、散点图矩阵(matrix)、星形图(star)、分位数图。这些图形的巧妙应用可以满足大多数用户的统计绘图要求。在一些非绘图命令中,还提供了绘制某些图形的功能,如生存分析中绘制生存曲线图、回归分析中残差图等。
8、矩阵代数是多元统计分析的重要工具,它提供了多元统计分析所需的矩阵基本运算,如矩阵加、积、逆、分解Cholesky、Kronecker内积等;还提供了一些高级运算,如特征根、特征向量、奇异值分解等;在执行了一些统计分析命令之后,还提供了一些系统矩阵,如估计系数向量、估计系数协方差矩阵等。
9、这是一个统计分析软件,但也有很强的程序语言功能,为用户开发应用提供了广阔的世界。用户可以充分发挥自己的聪明才智,熟练运用各种技能,真正做到自由。实际上,我们的ado文件(高级统计部分)都是用自己的语言写的。
10、它的统计分析能力远SPSS,在很多方面也超SAS!由于该软件在分析过程中将所有数据读入内存,并在计算完成后与磁盘交换数据,计算速度极快(一般来说,SAS的运算速度比SPS至少快一个数量级,而软件的一些模块实施相同功能的SAS快一个数量级!)软件也是用命令行操作,但是使用起来比SASu简单得多。其生存数据分析、纵向数据(重复测量11、数据分析等模块的功能甚至超过了SAS。该软件绘制的统计图形相当精美和有特色。
软件亮点
1、双差分法的官方命令。
Stata 17破解版有着双差分法(Difference-in-differences,简记DID)可能是最常用的测量方法。软件官方命令怎么可能没有DID?为此,软件及时推出了DID官方命令xtdidregress;其中,xt表示该命令适用于面板数据。
命令xtdidregress除了定期估计外,还允许最多指定三个分组变量(groupvariables)或两个分组变量和一个时间变量,从而进行三重差分法(Difference-in-differences-in-differences,简记DDD)的估计。
此外,针对重复截面数据(repeated-sectionaldata),即所谓的准面板(pseudo-paneldata),软件还推出了相关的新命令didregress,可以估计类似的didddatal。更重要的是,你可以用DID的官方命令轻松画出平行趋势图。
2、表格输出完美。
实证研究者经常需要以表格的形式将软件的多个回归结果输出到word文件中。虽然官方命令estimatestable可以完成这样的任务,但是比较死板;因此,软件用户通常使用非官方命令(如estout或outreg)来输出回归结果。因此,软件大大改善了原来的table命令,使用户可以很容易地以表格的形式报告回归结果(regression)或统计特征(summarystatistics)。
此外,您可以设计回归表格的风格(styles),并将其应用于创建的表格,然后将该表格输出到Word或其他形式的文件(包括PDF、HTML、LaTex、Excel、markdown等)。此外,您还可以使用新的前缀(prefix)collect来收集软件命令的各种估计结果。最后,软件还增加了Tablebuilder(表格创建器),让用户点击鼠标(point-and-click)创建表格。
3、Lasso的新功能。
作为高维回归(high-dimensionallregression)的常用工具,软件已经推出了一系列关于Lasso(Leastalutelshrinkagelandlectionloerator,也就是所谓的套索估计量)的官方命令。软件提供了更多关于lassoh的新功能。
使用Lasso估计处理效应模型。可以使用命令teffects来估计处理效应(treatmenteffects)模型,而命令lasso则用于估计协变量大的高维模型。软件将两者结合起来,它推出的新命令telasso可以估计包含许多协变量的处理效应模型。
使用BIC选择Lasso处罚参数。作为一种惩罚回归(penalized-regression),在估计Lasso时,需要选择惩罚参数(penalty-parameter)。可以使用交叉验证(cross-validation)、适应性方法(adaptive-method)或代入法(plugin)来选择惩罚参数。
在Stata 17破解版中,增加了selection(bic),可以使用贝叶斯信息准则(Bayesian-Information-Criterion)选择惩罚参数。此外,新增的估计后命令(postestimation?command)bicplot可以方便地将选择过程可视化。
使用Lasso处理聚类数据。对于聚类数据(clusterdata),由于每个聚类中的观测值都自相关的,通常的Lasso估计可能会导致偏差。使用命令lasso或elasticnet时,在软件中,您可以通过添加选项cluster(clustvar)来处理聚类数据。此外,对于使用Lasso进行统计推断的命令,例如poregress(表示partialing-outhregress),可以使用软件的新选择项cluster(clustvar)来获得聚类稳定的标准错误(cluster-robusthstandardherrrors)。
4、选择离散模型的新命令。
离散选择模型是微观计量经济学中常用的模型。在软件中,增加了以下离散选择模型的新命令:
多个面板逻辑模型(panel-multinomial-logit-model)。软件已经有了mlogit命令,用于横截面数据的多个逻辑模型。软件新增的xtmlogit命令可以使用面板数据来估计多个逻辑模型。这无疑是软件离散选择模型的一大进步,因为软件只能使用xtlogit或xtprobit来估计面板的二值选择模型。
零膨胀排序逻辑模型(zero-inflated-ordered-logit-model)。对于排序数据(orderedddata),可以使用软件命令ologit或oprobit进行估计。在实践中,有时最低类别在排序数据中占很大比例。如果把最低类别的取值记为零,就会出现所谓的零膨胀现象。此时,可以使用软件的新命令ziologit,估计更高效的零膨胀排序逻辑模型(zero-inflated-ordered-logit-model)。
5、长期数据的新命令。
长期数据(durationdata)常用于生物统计的生存分析(survivallanalysis),在经济学中也有广泛的用途,如失业的持续时间、婚姻的持续时间、王朝的寿命等。长期数据中经常存在删除(censoring)或合并问题。例如,当研究结束时,一些患者可能没有死亡;或者一些失业者还没有找到工作。
软件新推出的命令stintcox可以使用Cox模型来估计一个特殊的区间删除(interval-censored)数据。对于区间删除的数据,我们只知道事件发生在某个区间,却无法确定其发生时间;比如我们只知道癌症在两次体检之间复发。若忽略了长期数据中存在的区间删失问题,则会导致估计偏差。
6、贝叶斯计量经济学的全面升级。
在大数据时代,由于数据日益复杂和多样化,传统的基于频率学派的计量方法在处理一些问题时可能不方便使用,这使得贝叶斯学派的计量经济学逐渐兴起。频率学派认为待估计的参数是给定的未知数(fixedunknownparameters),而贝叶斯学派将未知参数视为服从某一分布的随机变量,可以根据新的样本信息随时更新为先验分布(priordistribution)。软件全面升级了Stata 17破解版中原有的贝叶斯统计学和计量经济学。
贝叶斯面板数据模型(Bayesian-data-models)。现有的软件面板命令包括xtreg(静态面板)、xtlogit或xtprobit(面板二值选择模型)、xtologit或xtoprobit(面板排序模型)等。如果要用贝叶斯方法来估计这些面板模型,只需在原命令之前加上前缀(prefix)bayes即可。
贝叶斯向量自回归模型(Bayesian-VAR-models)。向量自回归(Vectorautoregression,简记VAR)是一种常见的时间序列模型。在现有的软件中,可以使用命令var来估计VAR模型,而后续命令包括:使用fcast进行动态预测(dynamicforecast),以及使用irf估计forecastion(impulse-response-function)和forecast(forecast-variance-decomposition,简记feVD)。
在软件中,可以使用命令bayes:bayar(即在命令var之前添加前缀bayes)来估计贝叶斯的bayesfcast模型,然后使用bayesfcast进行动态预测;脉冲响应函数和预测误差方差的分解也可以类似地得到。
使用bayesfcast进行动态预测;
而且脉冲响应函数(IRF)和预测误差方差分解(FEVD)也可以类似地得到。
用贝叶斯方法估计VAR模型有两个好处。首先,VAR模型通常包含更多的参数。如果样本较小,估计结果不稳定。而且贝叶斯方法由于更容易整合先验信息(incorporating-prior-information),所以用小样本估计VAR模型更稳定。
其次,经典的VAR模型采用大样本理论进行统计推断和预测,需要假设计量服从正态分布,在小样本中难以满足。贝叶斯方法不使用大样本理论,也不需要接近正态的假设,所以更适合小样本。
贝叶斯多层模型(Bayesian-multilevel-models)。软件新推出的bayesmh命令可以估计一系列贝叶斯多层模型,包括单变量(univariate)或多变量(multivariate),甚至面板的生存时间模型(jointlongitudinalandsurvival-timels)型(SEM-typels)。
贝叶斯线性和非线性DSGE模型(Bayesianlinear-and-nonlinear-DSGE-models)。动态随机平衡(Dynamichastichgeneralequilibrium,DSGE)模型是宏观经济学的主流模型。可以使用命令dsge和dsgenl分别估计线性和非线性的dSGE模型,在软件中。
在Stata 17破解版中,只要在命令dsge和dsgenl之前添加前缀bayes,就可以估计相应的线性或非线性贝叶斯DSGE模型。可供用户选择的先验分布(priordistribution)多达30个,并且可以进行贝叶斯脉冲响应分析(BayesianirFunalysis),以及使用贝叶斯因子(Bayesianfactors)对比模型等。
7、非参数趋势检验。
有时候样本数据中有分组(例如,分为3组),这些分组有自然的排序(例如,记为1,2,3组),即所谓的排序分组(orderedgroups)。在这个排序分组的数据中,我们经常希望检查一个变量在这个分组排序中(例如,第1-3组)是否有某种趋势,例如,这个变量的值倾向越来越大,这就是所谓的testsforendacrosshorderedgroup。
因此,可以使用软件已有的命令nptrend来检查非参数Cuzick秩序(Cuzick-test-using-ranks)。软件的最新nptrend命令,除了Cuzick秩检验之外,还增加了Cochran-Armitagehtest三个非参数检验
软件标签 : Stata

























1条评论
真的可以,感谢
管理员回复:谢谢你的支持